
延續去年推出的GPT‑4o多模態模型,OpenAI近日向開發者推出GPT‑4.1系列模型,除了GPT-4.1,同時還有兩個較小的版本:GPT‑4.1 mini和GPT‑4.1 nano,前者價格較親民,便於開發者運用;後者更加輕量,根據OpenAI的說法,這3款模型均能處理最多 100 萬詞元(token)上下文長度,即提示中所包含的文字、圖片或影片能夠容納的篇幅更長,遠遠超過GPT‑4o 12.8萬詞元的上限。
OpenAI本週推出新一代生成式AI模型「GPT-4.1」系列,包括GPT-4.1、mini與nano三款,全面升級程式設計能力與指令遵從性。三者皆具備百萬Token上下文視窗,意味一次可處理約75萬字的資訊量,超越市面多數模型。
儘管GPT-4.1尚未導入ChatGPT產品,但已透過API對開發者開放,等同向Google Gemini 2.5 Pro與Anthropic Claude 3.7等競爭對手正面對決。OpenAI強調,GPT-4.1針對真實開發情境進行優化,是實現「AI軟體工程師」願景的關鍵里程碑。
OpenAI財務長傅萊爾(Sarah Friar)表示,公司目標是訓練可自主編碼、測試與撰寫技術文件的代理型AI工程師,提升企業開發效率。GPT-4.1的價格採取分級策略:
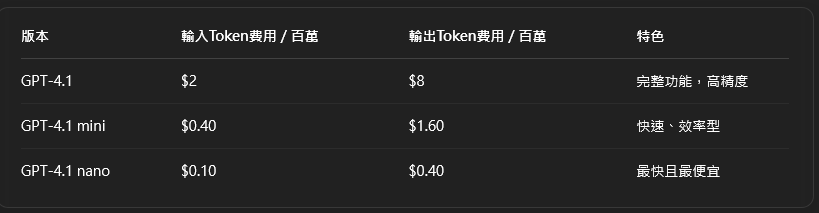
其中nano主打低延遲與高效率,預計將吸引中小型開發團隊及嵌入式應用領域。GPT-4.1在SWE-bench測試中獲得52%至54.6%分數,雖略低於Gemini 2.5 Pro(63.8%)與Claude 3.7(62.3%),但在前端開發、格式一致性與工具使用表現優異。
值得一提的是,OpenAI坦承在內部測試中發現,當輸入Token達百萬時,模型準確度由84%降至50%;此外,GPT-4.1對指令解析更偏向字面,需提供更明確提示。
與此同時,科技媒體《TechCrunch》報導,Google正積極拓展AI多模態能力。DeepMind執行長哈薩比斯(Demis Hassabis)近期表示,Google正整合語言模型Gemini與影片生成模型Veo,打造能理解現實物理法則的「全感知AI助理」。Veo 2已透過大量YouTube影片訓練,具備學習時序邏輯與動態場景的能力。
儘管Google強調訓練行為符合服務條款與創作者合約,但外界仍憂心使用者授權與內容所有權爭議。據悉,Google去年已修改條款,擴大可用於AI訓練的資料範圍,未來可能面臨歐盟與英國等地更嚴格的數據監管。
目前生成式AI戰場正邁入「any-to-any」生態,包括OpenAI整合語音、圖像與文字,Google主攻多模態助理,亞馬遜則計劃年底推出跨模態模型,整合Echo語音與AWS雲端服務。
專家指出,隨著AI模型進化為可同時「理解與創作」多種媒體形式的全感知架構,應用將橫跨劇情影片、教學動畫、互動簡報等高附加價值場景;不過,訓練全模態模型需要龐大的數據量與運算資源。
Google擁有YouTube這類原始資源,使其在影像與音訊資料訓練上具備天然優勢,但同時也引發對使用者授權、內容所有權與創作者權益的高度爭議。